Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM EST
It seems like the new motto for Silicon Valley for the last few years has been “Data is the new oil,” and for good reason. The number of companies employing machine learning-based AI technologies has exploded, and even a few years after all of this has kicked off in earnest, those numbers continue to grow. This form of AI is no longer just an academic thesis or curious research project, but instead machine learning has become an important part of the enterprise market, and the impact on enterprise hardware – both purchasing and development – would be difficult to overstate. This is the era of AI.
At first sight, the hardware choices for these kinds of applications seem simple: Intel Xeon CPUs for storing and preprocessing data, NVIDIA GPUs for (almost) everything AI. And indeed, this has largely been case for the last few years now. However, NVIDIA’s competitors have not been standing idly by the entire time – and that especially goes for Intel, whose enterprise market share all of this ultimately threatens. With everything from dedicated low-power inference processors to purpose-optimized Xeons, Intel is taking aim at every level of the AI market. The net result is that between all of these competitors, we’re seeing AI tackled from many different directions, and the hardware battle for AI era is insanely interesting in our humble opinion.
Today we’re taking a look at what’s perhaps the heart of Intel’s hardware in the AI space, Intel’s second-generation Xeon Scalable processors, better known as "Cascade Lake". Introduced a bit earlier this year, these new processors are still based on the same core Skylake architecture as the first-generation products, but incorporate a number of new instructions to speed up AI performance.
And as far as new technology goes, this is certainly the most interesting aspect of Cascade Lake. While we could talk about the three to six percent general CPU performance improvement, the 56 cores of Intel’s most expensive processor ever, and the "world record benchmarks," these small improvements are close to irrelevant for the near and mid-term future of the IT world. Just look at the very first slide of the Intel press & analyst briefing.

Internet of things, data engineering, and AI. That is where a large part of the growth, the innovation, and the future of IT will be. And this is where Intel wants to be.
Right now, NVIDIA has a virtual monopoly on the “sexiest” part of this market, which is deep learning and “massively parallel HPC” software. Thanks to a confluence of factors on the hardware and software sides, most of this software is run on NVIDIA GPUs and clusters. So to the general public, it looks likes NVIDIA owns the “AI market”, a picture that is not inaccurate, but also not complete. There’s a lot more to the AI market than just neural network inferencing, and in particular, everything that has to happen to feed the AI model with data gets very little attention. As a result, it’s neural networks and Terminator robots that get all the headlines, even though they’re just part of the of the picture. In reality, the processing web for AI applications is much more like the picture below.
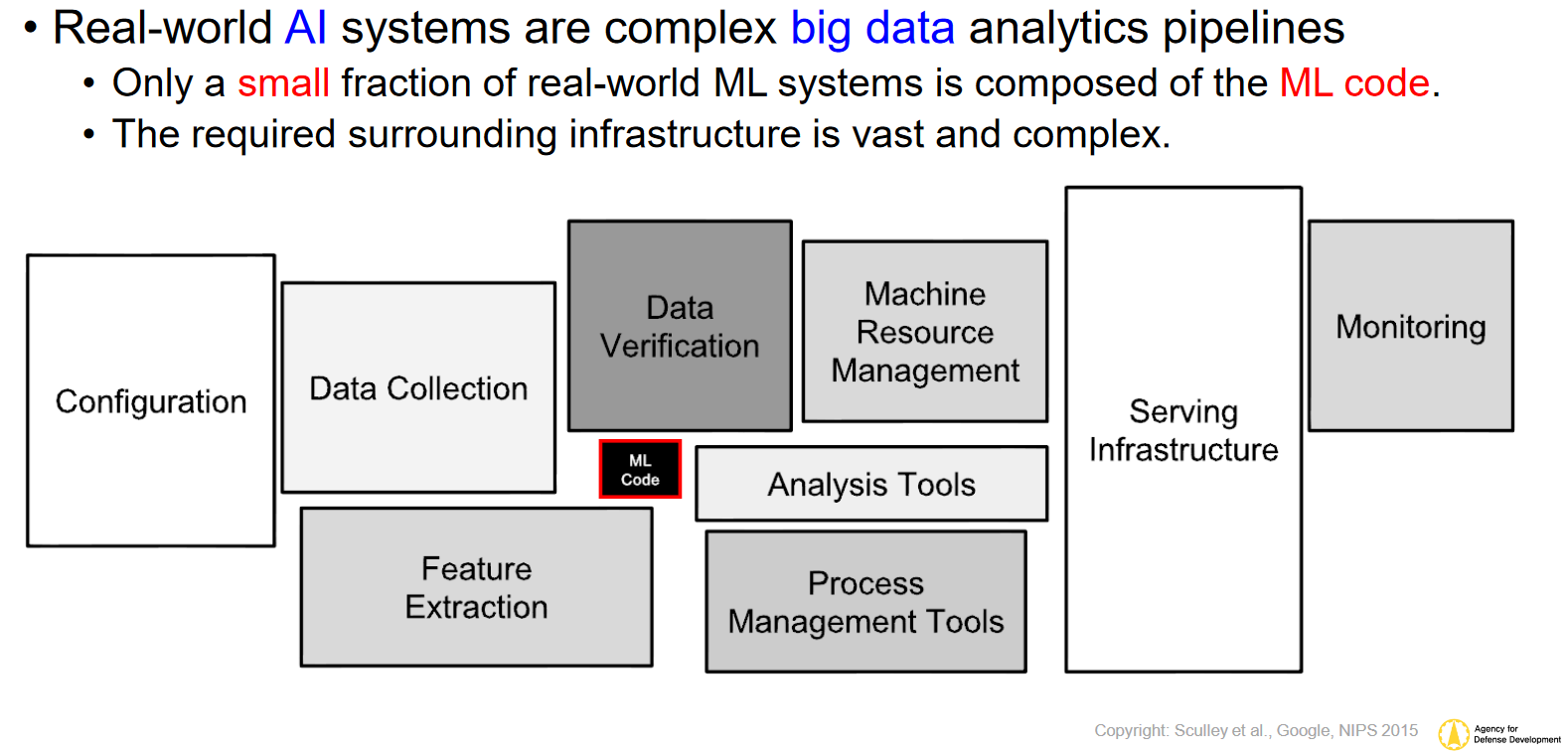
In short, actual machine learning code execution is only a very small part of the software tools necessary to build and AI Application.
Before you can even start, you have to ingest data, decompress, filter, reorder, map, and shuffle it around. Once everything is sorted and shuffled, you have to aggregate the data. As ML algorithms need large amounts of data to produce good predictions, that can be very processing memory intensive. Why? Let us delve a little deeper.








56 Comments
View All Comments
ballsystemlord - Saturday, August 3, 2019 - link
Spelling and grammar errors:"But it will have a impact on total energy consumption, which we will discuss."
"An" not "a":
"But it will have an impact on total energy consumption, which we will discuss."
"We our newest servers into virtual clusters to make better use of all those core."
Missing "s" and missing word. I guessed "combine".
"We combine our newest servers into virtual clusters to make better use of all those cores."
"For reasons unknown to us, we could get our 2.7 GHz 8280 to perform much better than the 2.1 GHz Xeon 8176."
The 8280 is only slightly faster in the table than the 8176. It is the 8180 that is missing from the table.
"However, since my group is mostly using TensorFlow as a deep learning framework, we tend to with stick with it."
Excess "with":
"However, since my group is mostly using TensorFlow as a deep learning framework, we tend to stick with it."
"It has been observed that using a larger batch can causes significant degradation in the quality of the model,..."
Remove plural form:
"It has been observed that using a larger batch can cause significant degradation in the quality of the model,..."
"...but in many applications a loss of even a few percent is a significant."
Excess "a":
"...but in many applications a loss of even a few percent is significant."
"LSTM however come with the disadvantage that they are a lot more bandwidth intensive."
Add an "s":
"LSTMs however come with the disadvantage that they are a lot more bandwidth intensive."
"LSTMs exhibit quite inefficient memory access pattern when executed on mobile GPUs due to the redundant data movements and limited off-chip bandwidth."
"pattern" should be plural because "LSTMs" is plural, I choose an "s":
"LSTMs exhibit quite inefficient memory access patterns when executed on mobile GPUs due to the redundant data movements and limited off-chip bandwidth."
"Of course, you have the make the most of the available AVX/AVX2/AVX512 SIMD power."
"to" not "the":
"Of course, you have to make the most of the available AVX/AVX2/AVX512 SIMD power."
"Also, this another data point that proves that CNNs might be one of the best use cases for GPUs."
Missing "is":
"Also, this is another data point that proves that CNNs might be one of the best use cases for GPUs."
"From a high-level workflow perfspective,..."
A joke, or a misspelling?
"... it's not enough if the new chips have to go head-to-head with a GPU in a task the latter doesn't completely suck at."
Traditionally, AT has had no language.
"... it's not enough if the new chips have to go head-to-head with a GPU in a task the latter is good at."
"It is been going on for a while,..."
"has" not "is":
"It has been going on for a while,..."
ballsystemlord - Saturday, August 3, 2019 - link
Thanks for the cool article!tmnvnbl - Tuesday, August 6, 2019 - link
Great read, especially liked the background and perspective next to the benchmark detailsdusk007 - Tuesday, August 6, 2019 - link
Great Article.I wouldn't call Apache Arrow a database though. It is a data format more akin to a file format like csv or parquet. It is not something that stores data for you and gives it to you. It is the how to store data in memory. Like CSV or Parquet are a "how to" store data in Files. More efficient less redundancy less overhead when access from different runtimes (Tensorflow, Spark, Pandas,..).
Love the article, I hope we get more of those. Also that huge performance optimizations are possible in this field just in software. Often renting compute in the cloud is cheaper than the man hours required to optimize though.
Emrickjack - Thursday, August 8, 2019 - link
Johan's new piece in 14 months! Looking forward to your Rome reviewEmrickjack - Thursday, August 8, 2019 - link
It More Information http://americanexpressconfirmcard.club/