Apple's M1 Pro, M1 Max SoCs Investigated: New Performance and Efficiency Heights
by Andrei Frumusanu on October 25, 2021 9:00 AM EST- Posted in
- Laptops
- Apple
- MacBook
- Apple M1 Pro
- Apple M1 Max
Huge Memory Bandwidth, but not for every Block
One highly intriguing aspect of the M1 Max, maybe less so for the M1 Pro, is the massive memory bandwidth that is available for the SoC.
Apple was keen to market their 400GB/s figure during the launch, but this number is so wild and out there that there’s just a lot of questions left open as to how the chip is able to take advantage of this kind of bandwidth, so it’s one of the first things to investigate.
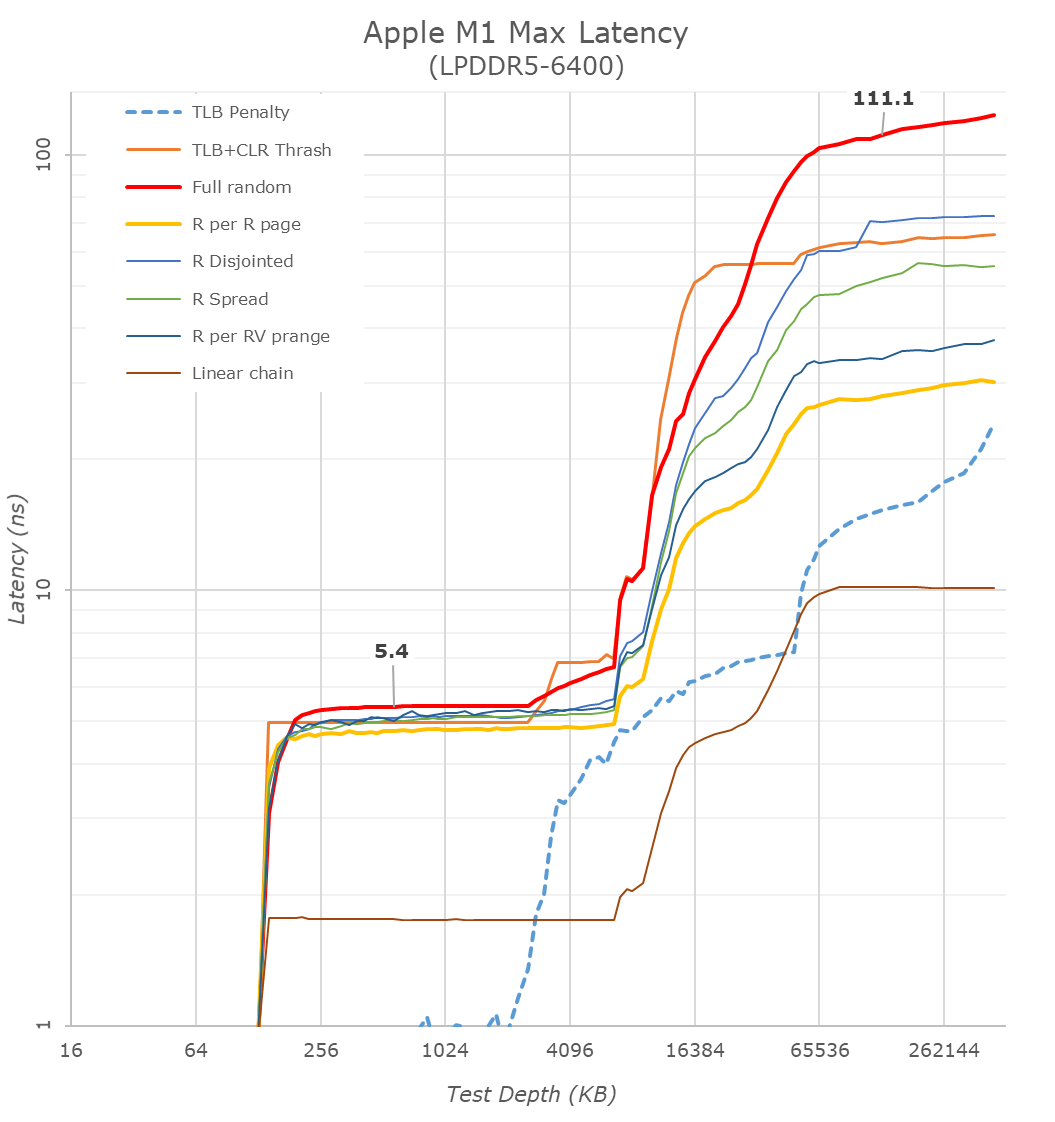
Starting off with our memory latency tests, the new M1 Max changes system memory behaviour quite significantly compared to what we’ve seen on the M1. On the core and L2 side of things, there haven’t been any changes and we consequently don’t see much alterations in terms of the results – it’s still a 3.2GHz peak core with 128KB of L1D at 3 cycles load-load latencies, and a 12MB L2 cache.
Where things are quite different is when we enter the system cache, instead of 8MB, on the M1 Max it’s now 48MB large, and also a lot more noticeable in the latency graph. While being much larger, it’s also evidently slower than the M1 SLC – the exact figures here depend on access pattern, but even the linear chain access shows that data has to travel a longer distance than the M1 and corresponding A-chips.
DRAM latency, even though on paper is faster for the M1 Max in terms of frequency on bandwidth, goes up this generation. At a 128MB comparable test depth, the new chip is roughly 15ns slower. The larger SLCs, more complex chip fabric, as well as possible worse timings on the part of the new LPDDR5 memory all could add to the regression we’re seeing here. In practical terms, because the SLC is so much bigger this generation, workloads latencies should still be lower for the M1 Max due to the higher cache hit rates, so performance shouldn’t regress.
A lot of people in the HPC audience were extremely intrigued to see a chip with such massive bandwidth – not because they care about GPU or other offload engines of the SoC, but because the possibility of the CPUs being able to have access to such immense bandwidth, something that otherwise is only possible to achieve on larger server-class CPUs that cost a multitude of what the new MacBook Pros are sold at. It was also one of the first things I tested out – to see exactly just how much bandwidth the CPU cores have access to.
Unfortunately, the news here isn’t the best case-scenario that we hoped for, as the M1 Max isn’t able to fully saturate the SoC bandwidth from just the CPU side;
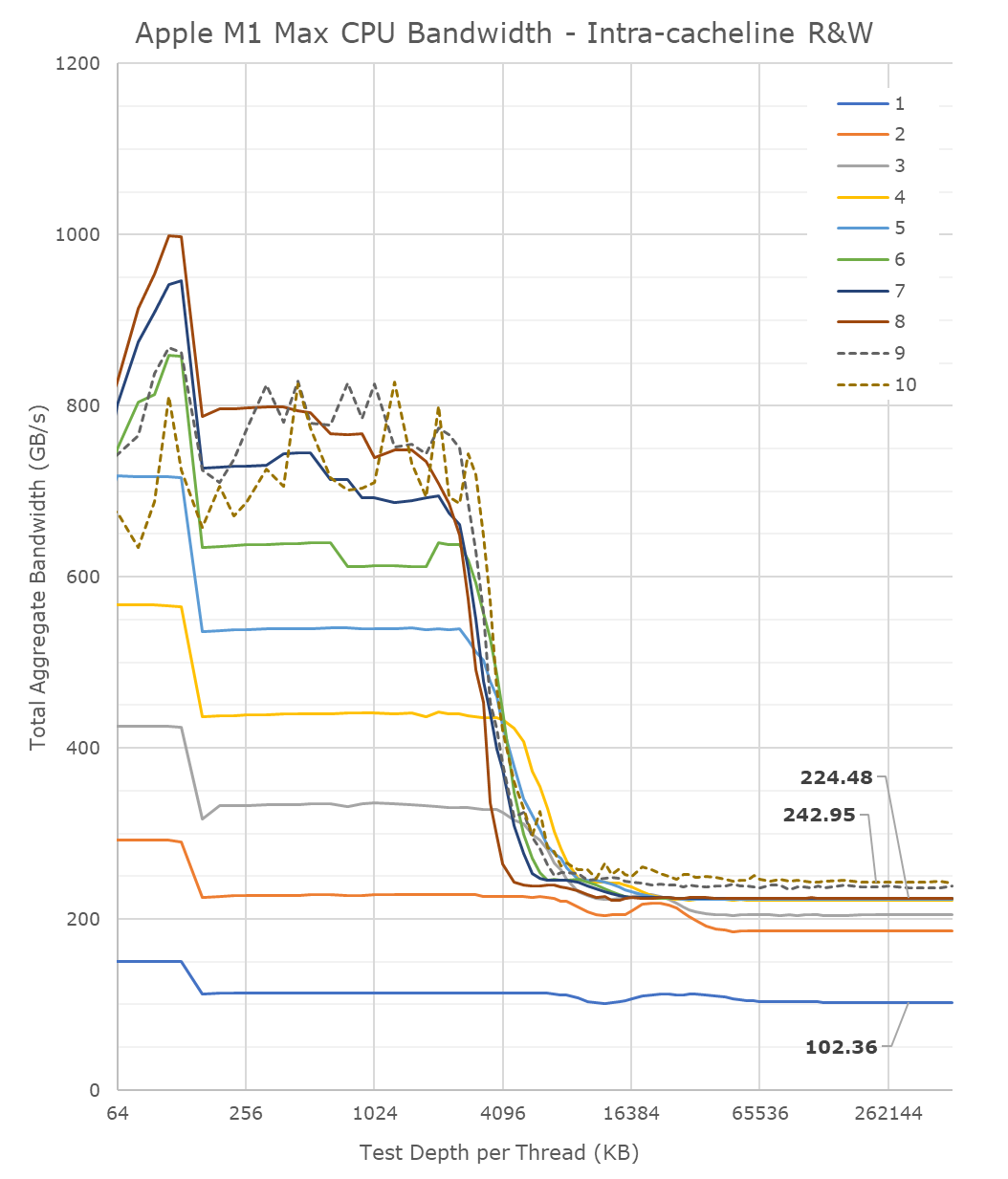
From a single core perspective, meaning from a single software thread, things are quite impressive for the chip, as it’s able to stress the memory fabric to up to 102GB/s. This is extremely impressive and outperforms any other design in the industry by multiple factors, we had already noted that the M1 chip was able to fully saturate its memory bandwidth with a single core and that the bottleneck had been on the DRAM itself. On the M1 Max, it seems that we’re hitting the limit of what a core can do – or more precisely, a limit to what the CPU cluster can do.
The little hump between 12MB and 64MB should be the SLC of 48MB in size, the reduction in BW at the 12MB figure signals that the core is somehow limited in bandwidth when evicting cache lines back to the upper memory system. Our test here consists of reading, modifying, and writing back cache lines, with a 1:1 R/W ratio.
Going from 1 core/threads to 2, what the system is actually doing is spreading the workload across the two performance clusters of the SoC, so both threads are on their own cluster and have full access to the 12MB of L2. The “hump” after 12MB reduces in size, ending earlier now at +24MB, which makes sense as the 48MB SLC is now shared amongst two cores. Bandwidth here increases to 186GB/s.
Adding a third thread there’s a bit of an imbalance across the clusters, DRAM bandwidth goes to 204GB/s, but a fourth thread lands us at 224GB/s and this appears to be the limit on the SoC fabric that the CPUs are able to achieve, as adding additional cores and threads beyond this point does not increase the bandwidth to DRAM at all. It’s only when the E-cores, which are in their own cluster, are added in, when the bandwidth is able to jump up again, to a maximum of 243GB/s.
While 243GB/s is massive, and overshadows any other design in the industry, it’s still quite far from the 409GB/s the chip is capable of. More importantly for the M1 Max, it’s only slightly higher than the 204GB/s limit of the M1 Pro, so from a CPU-only workload perspective, it doesn’t appear to make sense to get the Max if one is focused just on CPU bandwidth.
That begs the question, why does the M1 Max have such massive bandwidth? The GPU naturally comes to mind, however in my testing, I’ve had extreme trouble to find workloads that would stress the GPU sufficiently to take advantage of the available bandwidth. Granted, this is also an issue of lacking workloads, but for actual 3D rendering and benchmarks, I haven’t seen the GPU use more than 90GB/s (measured via system performance counters). While I’m sure there’s some productivity workload out there where the GPU is able to stretch its legs, we haven’t been able to identify them yet.
That leaves everything else which is on the SoC, media engine, NPU, and just workloads that would simply stress all parts of the chip at the same time. The new media engine on the M1 Pro and Max are now able to decode and encode ProRes RAW formats, the above clip is a 5K 12bit sample with a bitrate of 1.59Gbps, and the M1 Max is not only able to play it back in real-time, it’s able to do it at multiple times the speed, with seamless immediate seeking. Doing the same thing on my 5900X machine results in single-digit frames. The SoC DRAM bandwidth while seeking around was at around 40-50GB/s – I imagine that workloads that stress CPU, GPU, media engines all at the same time would be able to take advantage of the full system memory bandwidth, and allow the M1 Max to stretch its legs and differentiate itself more from the M1 Pro and other systems.








493 Comments
View All Comments
zodiacfml - Monday, October 25, 2021 - link
Nice, it falls where I expected it since the announcement. Apple is now playing with the 5nm process like it is nothing.LuckyWhale - Monday, October 25, 2021 - link
Seems like a hasty and rushed article by a fanboy. So lacking (perhaps on purpose) in real-world general benchmarks; Could have added some encoding or compression, image manipulation, etc. benchmarks for several competing systems.Hifihedgehog - Monday, October 25, 2021 - link
> Seems like a hasty and rushed article by a fanboy.Unlike Ian Cutress who is down to earth and a blast to send questions or pose hypotheses to, the author on occasion has been very rude and condescending if you disagree. Never mind his statements like this one from Andre that ARM would make you question his motives: "No - Apple is indeed special and many Arm ISA things happen because of Apple." ARM ISA has been progressing more and more automonously and independently from Apple since the 2013 arm64 contribute. Apple indeed has a 1-2 year lead over the rest of industry thanks to bets made around a decade ago, but they are not heaven's never-failing gift to humanity. Statements like this from Andrei should give you all the knowledge you need about his bias.
ikjadoon - Monday, October 25, 2021 - link
I think the AT team work together on various pieces. Ian is, after all, the primary Intel & AMD author here, so his work is seemingly used here, too.>many Arm ISA things happen because of Apple
You realise that statement has been directly validated by Apple employees...publicly? See Shac Ron, who commented in the very thread you're referring to.
It's not that unexpected...Arm Ltd. was literally founded by Acorn, Apple and VLSI. An Apple VP was appointed as Arm's first CEO. Former Arm employees have confirmed that Apple was responsible for Arm's name removing all mention of "Acorn". Literally from Wikipedia, mate:
>The company was founded in November 1990 as Advanced RISC Machines Ltd and structured as a joint venture between Acorn Computers, Apple, and VLSI Technology. Acorn provided 12 employees, VLSI provided tools, Apple provided $3 million investment. Larry Tesler, Apple VP was a key person and the first CEO at the joint venture.
Then this...
>Apple indeed has a 1-2 year lead
If you think Intel (and AMD) need just 1-2 years to overcome a 4x perf/watt gap, I'm not sure how long you have read AnandTech or followed this industry. If that timeline was anything close to true, we should see AMD & Intel matching M1 perf/watt next month, right? M1 launched a year ago.
>they are not heaven's never-failing gift to humanity
Don't think anyone has made conclusion, have they? These are CPU reviews: there's data and there's straightforward conclusions from the data.
Hifihedgehog - Monday, October 25, 2021 - link
If you are referencing the data, then you would observe it is a 2X efficiency advantage, not your grossly over-exaggerated 4X. Unless, of course, you are referencing Apple’s 3080 Laptop claims. The numbers here show 3060 gaming performance. Adobe Premiere Pro, meanwhile, which has been made enhanced for M series silicon since July, is only showing numbers on par with RTX 3050 Ti coming out of M1 Max. Let’s be objective but Andrei needs to broaden his benchmark horizons:https://twitter.com/TheRichWoods/status/1452639861...
ikjadoon - Tuesday, October 26, 2021 - link
lmao: what kind of basic YouTube comment is this? You're thoroughly confused. And ignored every other silly point that was neatly debunked...1) Nope: XDA admits in their actual review that Premiere Pro hasn't yet been updated to activate the M1 Pro / Max video engines, lmao, and that's why it appeared "slow". Do you just copy-paste tweets that agree with you with zero critical review? XDA made it obvious in their review (which you happily refused to link).
https://www.xda-developers.com/apple-macbook-pro-2...
>I checked with Apple on the jarring discrepancy between Final Cut Pro and Adobe Premiere Pro rendering times (1:35 vs 21:11!) and a representative from Apple said it’s because Adobe Premiere Pro has not been optimized to use the M1 Pro/Max’ ProRes hardware for video encoding.
2) You simply cannot read and I'm done wasting my time. Thanks for making me write this out, though: much easier to debunk other illiterate YouTube commenters. 😂
Cinebench R23 ST: M1 Max has 4.7x higher perf/W than the i9-11980HK
Cinebench R23 MT: M1 Max has 2.6x higher perf/W than the i9-11980HK
SPEC2017 502 ST: M1 Max has 2.9x higher perf/W than the i9-11980HK
SPEC2017 502 MT: M1 Max has 4.0x higher perf/W than the i9-11980HK
SPEC2017 511 ST: M1 Max has 3.5x higher perf/W than the i9-11980HK
SPEC2017 511 MT: M1 Max has 2.9x higher perf/W than the i9-11980HK
SPEC2017 503 ST: M1 Max has 2.4x higher perf/W than the i9-11980HK
SPEC2017 503 MT: M1 Max has 6.3x higher perf/W than the i9-11980HK
The geometric mean perf/W improvement is 3.5x. :) Thank you for the laughs, though. Now I know who actually doesn't read the articles!
If you want objectivity, then bring real data next time. Please find someone else to "debate" lmao. See you once Intel & AMD to release their "just 1-2 years behind" M1 competitors in the next two months.
Will eagerly await for AnandTech's review...
ikjadoon - Monday, October 25, 2021 - link
Did you read the article, though? AnandTech tested every single thing you asked for...All benchmarks need to be standardized between arm vs x86, Windows vs macOS, etc. What validated, repeatable cross-ISA, cross-OS "real-world" software do you suggest?
Today, that is SPEC2017...which would you have understood had you read the article:
557.xz_r = compression
525.x264_r = encoding
538.imagick_r = image manipulation
They also ran PugetBench's Premiere Pro, one of the few Apple Silicon-native production applications.
michael2k - Monday, October 25, 2021 - link
They did: That's what SPEC2017 was and they compared it to the Ryzen 5980HS and Core i9-11980HKvladx - Monday, October 25, 2021 - link
Yes at this point it's quite obvious Andrei is a big Apple fanboy with how he tries to oversell the performance of the Max SoC with synthetic benchmarks.FurryFireball - Monday, October 25, 2021 - link
For games why don’t you use one that was converted for M1? I know world of Warcraft was made native for M1 by blizzard so that would give you a better idea of how well it would do in gaming. Wow still can beat down a 3080ti if you max everything out so it’s not a slouch of a game to benchmark to.