The Armari Magnetar X64T Workstation OC Review: 128 Threads at 4.0 GHz, Sustained!
by Dr. Ian Cutress on September 9, 2020 12:00 PM EST- Posted in
- Desktop
- Systems
- AMD
- OC Systems
- ThreadRipper
- 3990X
- Armari
- Magnetar
- X64T
- Rendering
Rendering Benchmark Performance
On the AnandTech benchmark side of the equation, if you read the recent article on our #CPUOverload project, we detail the 150 or so tests in our new testing suite that we aim to perform on as many CPUs as possible. These tests are designed for a wide range of systems, from highly responsive systems for user access, low powered devices, gaming machines, workstations, and the enterprise market, with a variation to cover a wide range of markets. All of our results will be published in our benchmark database, Bench, and the key ones that form the focus of the Magnetar are compared on this page.
The Magnetar X64T is a workstation through and through, with a focus on rendering, simulation, and hard core math. We’ve currently tested our new benchmark suite on around 20 processors, and out of these we have the following comparison points:
| AnandTech Test Systems | ||
| AnandTech | Cores | DRAM |
| Armari Magnetar X64T | 64C / 128T | 4 Ch DDR4-3200 C20 |
| TR3 3990X | 64C / 128T | 4 Ch DDR4-3200 C15 |
| Xeon W-3175X | 28C / 56T | 6 Ch DDR4-2666 C20 |
| Xeon Gold 6258R | 28C / 56T | 6 Ch DDR-2933 C21 |
The key win here for the Magnetar X64T is going to be multithreaded performance, where it hits 3.9-4.1 GHz all-core sustained depending on the test.
The key things to note here are between the Magnetar X64T and our stock 3990X. This system typically ships with DDR4-3866 C18, however due to a last minute system rebuild before the system was shipped, a coolant accident meant that for stability, the memory was replaced. As a result, we’re going to see some circumstances where the faster memory of the stock 3990X will in out: in our peak bandwidth test, the X64T scored 81 GB/s, and our 3990X scored 85 GB/s. The four-channel Threadripper also has a bandwidth deficit to the six-channel Xeons, which is noticeable in a couple of tests. However, the tests where the Magnetar wins, it’s usually by a lot, as shown in the previous page.
Out of these CPUs, nothing else we’ve tested since our new benchmark suite started comes close. I think the key product we’re missing here is a 64-core EPYC or Threadripper Pro, which we’re hoping to receive soon.
Here are our rendering benchmark results.
Blender 2.83 LTS: Link
One of the popular tools for rendering is Blender, with it being a public open source project that anyone in the animation industry can get involved in. This extends to conferences, use in films and VR, with a dedicated Blender Institute, and everything you might expect from a professional software package (except perhaps a professional grade support package). With it being open-source, studios can customize it in as many ways as they need to get the results they require. It ends up being a big optimization target for both Intel and AMD in this regard.
For benchmarking purposes, Blender offers a benchmark suite of tests: six tests varying in complexity and difficulty for any system of CPUs and GPUs to render up to several hours compute time, even on GPUs commonly associated with rendering tools. Unfortunately what was pushed to the community wasn’t friendly for automation purposes, with there being no command line, no way to isolate one of the tests, and no way to get the data out in a sufficient manner.
To that end, we fell back to one rendering a frame from a detailed project. Most reviews, as we have done in the past, focus on one of the classic Blender renders, known as BMW_27. It can take anywhere from a few minutes to almost an hour on a regular system. However now that Blender has moved onto a Long Term Support model (LTS) with the latest 2.83 release, we decided to go for something different.

We use this scene, called PartyTug at 6AM by Ian Hubert, which is the official image of Blender 2.83. It is 44.3 MB in size, and uses some of the more modern compute properties of Blender. As it is more complex than the BMW scene, but uses different aspects of the compute model, time to process is roughly similar to before. We loop the scene for 10 minutes, taking the average time of the completions taken. Blender offers a command-line tool for batch commands, and we redirect the output into a text file.

Over the standard Threadripper system, the X64T is around 32% faster in our Blender scene.
Corona 1.3: Link
Corona is billed as a popular high-performance photorealistic rendering engine for 3ds Max, with development for Cinema 4D support as well. In order to promote the software, the developers produced a downloadable benchmark on the 1.3 version of the software, with a ray-traced scene involving a military vehicle and a lot of foliage. The software does multiple passes, calculating the scene, geometry, preconditioning and rendering, with performance measured in the time to finish the benchmark (the official metric used on their website) or in rays per second (the metric we use to offer a more linear scale).
The standard benchmark provided by Corona is interface driven: the scene is calculated and displayed in front of the user, with the ability to upload the result to their online database. We got in contact with the developers, who provided us with a non-interface version that allowed for command-line entry and retrieval of the results very easily. We loop around the benchmark five times, waiting 60 seconds between each, and taking an overall average. The time to run this benchmark can be around 10 minutes on a Core i9, up to over an hour on a quad-core 2014 AMD processor or dual-core Pentium.
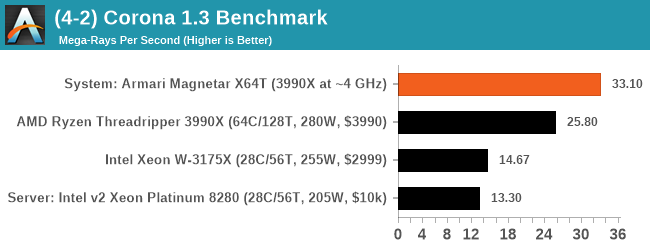
Corona typically scales very well with core count and frequency, and here the X64T has a 28% lead over a stock 3990X.
V-Ray: Link
We have a couple of renderers and ray tracers in our suite already, however V-Ray’s benchmark came through for a requested benchmark enough for us to roll it into our suite. Built by ChaosGroup, V-Ray is a 3D rendering package compatible with a number of popular commercial imaging applications, such as 3ds Max, Maya, Undreal, Cinema 4D, and Blender.

We run the standard standalone benchmark application, but in an automated fashion to pull out the result in the form of kilosamples/second. We run the test six times and take an average of the valid results.

Similarly, the X64T has a 30% performance gain.
Cinebench R20: Link
Another common stable of a benchmark suite is Cinebench. Based on Cinema4D, Cinebench is a purpose built benchmark machine that renders a scene with both single and multi-threaded options. The scene is identical in both cases. The R20 version means that it targets Cinema 4D R20, a slightly older version of the software which is currently on version R21. Cinebench R20 was launched given that the R15 version had been out a long time, and despite the difference between the benchmark and the latest version of the software on which it is based, Cinebench results are often quoted a lot in marketing materials.
Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath. The results are output as a score from the software, which is directly proportional to the time taken. Using the benchmark flags for single CPU and multi-CPU workloads, we run the software from the command line which opens the test, runs it, and dumps the result into the console which is redirected to a text file. The test is repeated for 10 minutes for both ST and MT, and then the runs averaged.

Cinebench go brrrr. I will never get tired of a quick R20 run like this, at around 15 seconds for the X64T. Performance is +35% over the stock 3990X.








96 Comments
View All Comments
KillgoreTrout - Wednesday, September 9, 2020 - link
Intelolclose - Wednesday, September 9, 2020 - link
This shows some awesome performance but the tradeoff is the limited memory capacity. If you don;t need that great. If you do then Threadripper is not the best option.twotwotwo - Wednesday, September 9, 2020 - link
Hmm, so you're saying AnandTech needs a 3995WX or 2x7742 workstation sample? :)close - Wednesday, September 9, 2020 - link
A stack of them even :). Thing is memory support doesn't make for a more interesting review, doesn't really change any of the bars there. It's a tick box "supports up to 2TB of RAM".Memory support is of the things that makes an otherwise absurdly expensive workstation like the Mac Pro attractive (that and the fact that for whoever needs to stay within that ecosystem the licenses alone probably cost more than a stack of Pros).
oleyska - Wednesday, September 9, 2020 - link
https://www.lenovo.com/no/no/thinkstation-p620will probably be able to help.
close - Wednesday, September 9, 2020 - link
The P620 supports up to 512GB of RAM. Generally OK and probably delivers on every other aspect but for those few that need 1.5-2TB of RAM it still wouldn't cut it. For that the go to is usually a Xeon, or EPYC more recently.schujj07 - Wednesday, September 9, 2020 - link
Remember that Threadripper Pro supports 2TB of RAM in an 8 channel setup. While getting 2TB/socket isn't cheap, it is a possibility.rbanffy - Thursday, September 10, 2020 - link
I wonder the impact of the 8-channel config on single-threaded workloads. The 256MB of L3 is already quite ample to the point I'm unsure how diminished are the returns at that point.sjerra - Monday, September 28, 2020 - link
This is my biggest concern and rarely considered or studied in reviews. Design space exploration.CAE over many design variations. Hundreds of design variations calculated as much as possible in parallel over the available cores (one core per variation, but each grabbing a slice of the memory). I've tested this on a 7960xe, purposely running it on dual channel and quad channel memory. On dual channel memory, at 12 parallel calculations (so 6 cores/channel) I measured a 46% increase in the calculation time / sample. in quad channel, at 12 parallel calculations (so 3 cores/ channel) I already measured a 30% reduction per calculation. (can anyone explain the worse results for quad channel?)
Either way, it leaves me to conclude that 64 cores with 4 channel memory for this type of workload is a big no go. Something to keep in mind. I'm now spec'ing a dual processor workstation with two lower core count processors and fully populated memory channels. (either epic (2x32c, 16 channels) or Xeon (2x24c, 12 channels). still deciding).
sjerra - Monday, September 28, 2020 - link
Edit: 30% increase of course.