Intel Unveils Lunar Lake Architecture: New P and E cores, Xe2-LPG Graphics, New NPU 4 Brings More AI Performance
by Gavin Bonshor on June 3, 2024 11:00 PM EST
Intel this morning is lifting the lid on some of the finer architectural and technical details about its upcoming Lunar Lake SoC – the chip that will be the next generation of Core Ultra mobile processors. Once again holding one of their increasingly regular Tech Tour events for media and analysts, Intel this time set up shop in Taipei just before the beginning of Computex 2024. During the Tech Tour, Intel disclosed numerous facets of Lunar Lake, including their new P-Core design codenamed Lion Cove and a new wave of E-cores that are a bit more like Meteor Lake's pioneering Low Power Island E-Cores. Also disclosed was the Intel NPU 4, which Intel claims delivers up to 48 TOPS, surpassing Microsoft's Copilot+ requirements for the new age of AI PCs.
Intel's Lunar Lake represents a strategic evolution in their mobile SoC lineup, building on their Meteor Lake launch last year, focusing on enhancing power efficiency and optimizing performance across the board. Lunar Lake dynamically allocates tasks to efficient cores (E-cores) or performance cores (P-cores) based on workload demands by leveraging advanced scheduling mechanisms, which are assigned to ensure optimal power usage and performance. Still, once again, Intel Thread Director, along with Windows 11, plays a pivotal role in this process, guiding the OS scheduler to make real-time adjustments that balance efficiency with computational power depending on the intensity of the workload.
| Intel CPU Architecture Generations | |||||
| Alder/Raptor Lake | Meteor Lake |
Lunar Lake |
Arrow Lake |
Panther Lake |
|
| P-Core Architecture | Golden Cove/ Raptor Cove |
Redwood Cove | Lion Cove | Lion Cove | Cougar Cove? |
| E-Core Architecture | Gracemont | Crestmont | Skymont | Crestmont? | Darkmont? |
| GPU Architecture | Xe-LP | Xe-LPG | Xe2 | Xe2? | ? |
| NPU Architecture | N/A | NPU 3720 | NPU 4 | ? | ? |
| Active Tiles | 1 (Monolithic) | 4 | 2 | 4? | ? |
| Manufacturing Processes | Intel 7 | Intel 4 + TSMC N6 + TSMC N5 | TSMC N3B + TSMC N6 | Intel 20A + More | Intel 18A |
| Segment | Mobile + Desktop | Mobile | LP Mobile | HP Mobile + Desktop | Mobile? |
| Release Date (OEM) | Q4'2021 | Q4'2023 | Q3'2024 | Q4'2024 | 2025 |
Lunar Lake: Designed By Intel, Built By TSMC (& Assembled By Intel)
While there are many aspects of Lunar Lake to dive into, perhaps it's best we start with what's sure to be the most eye-catching: who's building it.
Intel's Lunar Lake tiles are not being fabbed using any of their own foundry facilities – a sharp departure from historical precedence, and even the recent Meteor Lake, where the compute tile was made using the Intel 4 process. Instead, both tiles of the disaggregated Lunar Lake are being fabbed over at TSMC, using a mix of TSMC's N3B and N6 processes. In 2021 Intel set about freeing their chip design groups to use the best foundry they could – be it internal or external – and there's no place that's more apparent than here.
Overall, Lunar Lake represents their second generation of disaggregated SoC architecture for the mobile market, replacing the Meteor Lake architecture in the lower-end space. At this time, Intel has disclosed that it uses a 4P+4E (8 core) design, with hyper-threading/SMT disabled, so the total thread count supported by the processor is simply the number of CPU cores, e.g., 4P+4E/8T.

The build-up of Lunar Lake combines a synergetic collaboration between Intel’s architectural design team and TSMC's manufacturing process nodes to bring the latest Lion Cove P-cores to Lunar Lake, which boosts Intel's architectural IPC as you would expect from a new generation. At the same time, Intel also introduces the Skymont E-cores, which replace the Low Power Island Cresmont E-cores of Meteor Lake. Notably, however, these E-cores don't connect to the ring bus like the P-cores, which makes them a sort of hybrid LP E-core, combining the efficiency gains of the more advanced TSMC N3B node with the double-digit gains in IPC over the previous Crestmont cores.
The entire compute tile, including the P and E-cores, is built on TSMC's N3B node, while the SoC tile is made using the TSMC N6 node.
At a higher level, Intel is once again using their Foveros packaging technology here. Both the compute and SoC (now the "Platform Controller") tiles sit on top of a base tile, which provides high-speed/low-power routing between the tiles, and further connectivity to the rest of the chip and beyond.
In another first for a mainstream Intel Core product, the Lunar Lake SoC platform also includes up to 32 GB of LPDDR5X memory on the chip package itself. This is arranged as a pair of 64-bit memory chips, offering a total 128-bit memory interface. As with other vendors using on-package memory, this change means that users can't just upgrade DRAM at-will, and the memory configurations for Lunar Lake will ultimately be determined by what SKUs Intel opts to ship.
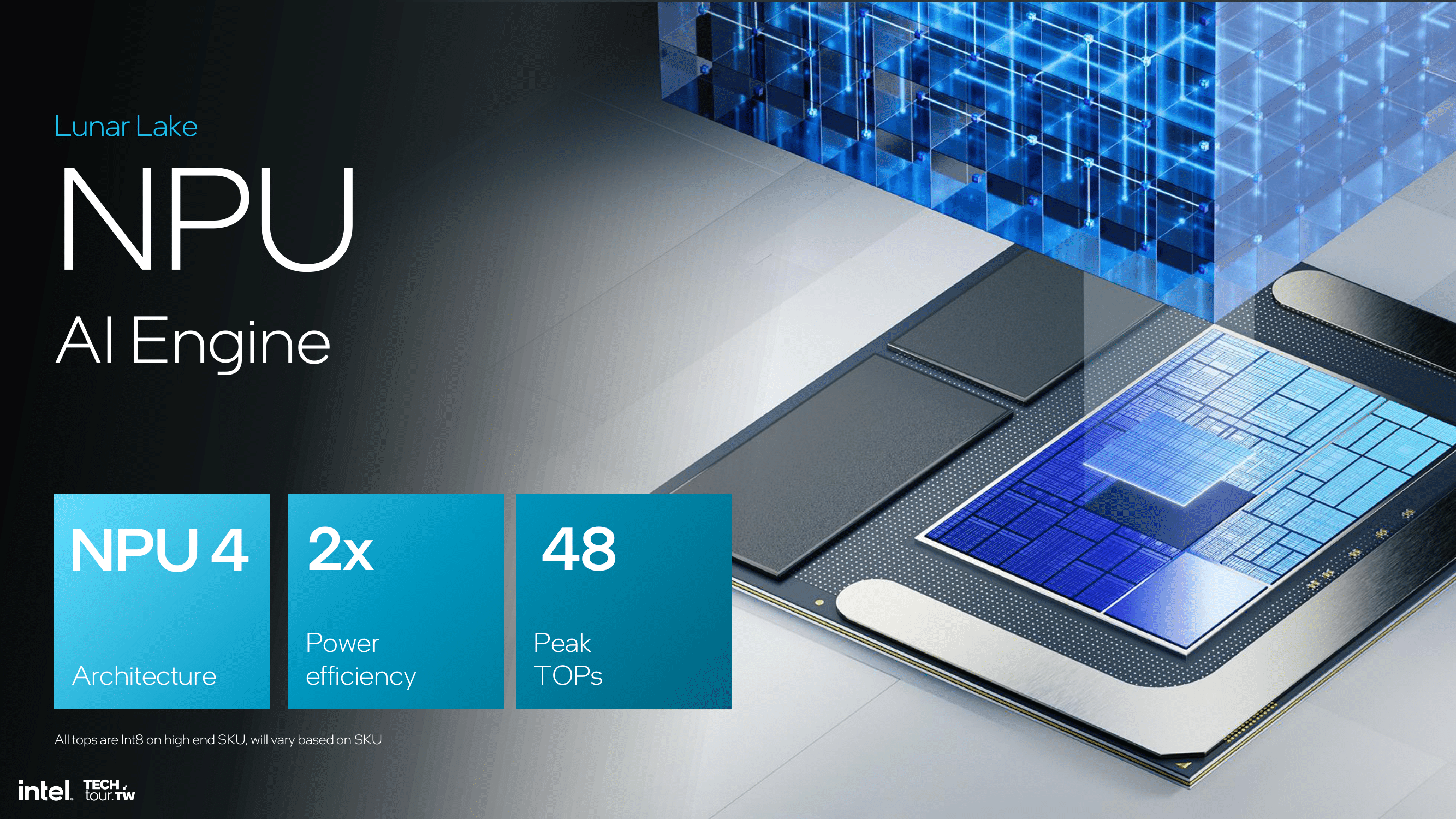
With Lunar Lake, Intel is also strongly focusing on AI, as the architecture integrates a new NPU called NPU 4. This NPU is rated for up to 48 TOPS of INT8 performance, thus making it Microsoft Copilot+ AI PC ready. This is the bar all of the PC SoC vendors are aiming for, including AMD and Qualcomm too.
Intel's integrated GPU will also be a contributing player here. While not the highly efficient machine that the dedicated NPU is, the Arc Xe2-LPG brings dozens of additional T(FL)OPS of performance with it, and some additional flexibility an NPU doesn't come with. Which is why you'll also see Intel rating the performance of these chips in terms of total platform TOPS – in this case, 120 TOPS.
Intel's collaboration with Microsoft further enhances workload management through the fabled Intel Thread Director, optimized for applications such as the Copilot assistant. Given the time of the introduction of Lunar Lake, it somewhat sets the stage for a Q3 2024 launch, which coincides with the holiday 2024 market.
Intel Lunar Lake: Updating Intel Thread Director & Power Management Improvements
To say that energy efficiency is a key goal for Lunar Lake would be an understatement. For as much as Intel is riding high in the mobile PC CPU market (AMD's share there is still but a fraction), the company has been feeling the pressure over the last few years from customer-turned-rival Apple, whose M-series Apple Silicon has been setting the bar for power efficiency over the last few years. And now with Qualcomm attempting to do the same things for the Windows ecosystem with their forthcoming Snapdragon X chips, Intel is preparing to make their own power play.
Intel's Thread Director and power management updates for Lunar Lake show various and significant improvements compared to Meteor Lake. The Thread Director uses a heterogeneous scheduling policy, initially assigning tasks to a single E-core and expanding to other E-cores or P-cores as and when needed. OS containment zones are designed to limit tasks to specific cores, which directly improves power efficiency and delivers the performance needed by the right core for the workload at hand. Integration with power management systems and a quad array of Power Management Controllers (PMC) further allows the chip, in concert with Windows 11, to make context-aware adjustments, ensuring optimal performance with minimal power usage and wastage.
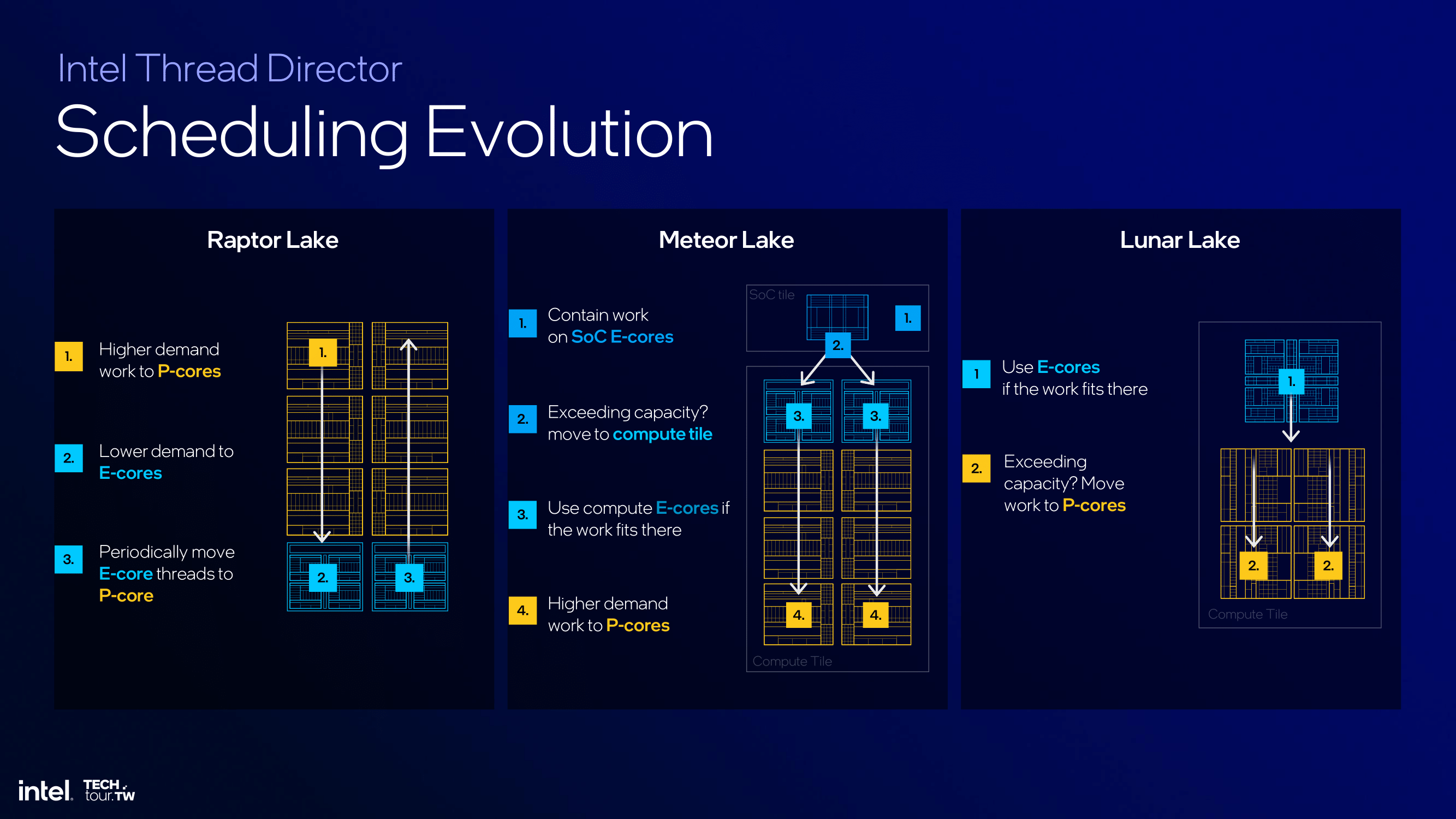
Lunar Lake's scheduling strategy effectively handles power-sensitive applications. One example Intel gave is that video conferencing tasks are kept within the efficiency core cluster, utilizing the E-cores to maintain performance while reducing power consumption by up to 35%, as shown by Intel's provided data. These improvements are achieved through collaboration with OS developers such as Microsoft for seamless integration for optimizing for the best balance between power consumption and performance.

Focusing on the power management system for Lunar Lake, Intel uses its SoC power management, operating in efficiency, balance, and performance modes tailored and designed to adapt to whatever the demands of the workload at the time of operation. This multi-layered approach allows the Lunar Lake SoC to operate efficiently. Again, much like the Intel Thread Director, the PMCs can balance power usage with performance needs.

Intel further plans to enhance the Thread Director by increasing scenario granularity, implementing AI-based scheduling hints, and enabling cross-IP scheduling within Windows 11. These enhancements essentially equate to workload management designed to boost overall power efficiency and deliver performance across various applications when needed without wasting power budget by allocating lighter tasks to the higher power P-cores.
Over the next few pages, we'll explore the new P and E cores and Intel's update to ther integrated Arc Xe (Xe2-LPG) graphics.








90 Comments
View All Comments
kwohlt - Tuesday, June 4, 2024 - link
20A is best thought of as an internal only, early sampling of 18A for use on the Compute Tile.But LNL differs from ARL in that its compute tile also contains the iGPU and NPU, making 20A not an appropriate choice. 18A would've been the node Intel would've needed, but that's not until next year (coincidently, LNL's direct successor, PNL, will use 18A for it's unified compute tile instead of TSMC) Reply
Blastdoor - Wednesday, June 5, 2024 - link
Or we could take it to mean that intel reserved a lot of N3B capacity and so figured they might as well use it. Like Apple, they will probably be looking to get off of N3B ASAP. While Apple moves to N3E, Intel will leap ahead to A18. ReplyThe Hardcard - Wednesday, June 5, 2024 - link
Barring newly announced delays, TSMC will hit volume on N2 in the same timeframe as volume on Intel A18. Apple’s move to N3E has happened. N2 in 2025. Replyrgreen1983 - Tuesday, June 4, 2024 - link
"This uplift is noticed, especially in the betterment of its hyper-threading, whereby improved IPC by 30%, dynamic power efficiency improved by 20%, and previous technologies, in balancing, without increasing the core area, in a commitment of Intel to better performance, within existing physical constraints."So hyper threading is bother present and improved, yet they disabled it? This seems non sensical Reply
meacupla - Tuesday, June 4, 2024 - link
From what I have read and seen from other tech sites, Intel disabled HT because it wasn't working properly with E-cores.Disabling HT improves performance and efficiency, because the E-cores get utilized, instead of sitting idle on low power loads. Reply
rgreen1983 - Tuesday, June 4, 2024 - link
I'm not asking why they disabled HT, we've known they were going to disable HT for some time. Disabling HT out of the box doesn't do anything because we've always been able to disable HT ourselves. I'm asking why they improved it if they are going to disable it, why waste a bunch of transistors and die area on a disabled feature? And if maybe the decision came too late to be removed, why brag about a thing that isn't even enabled? ReplyDrumsticks - Tuesday, June 4, 2024 - link
Unfortunately, this feels like word salad from Anandtech. I won’t speculate how or why it was left in, or why Anandtech is quoting a 30% gain in IPC that is nowhere in Intel’s slides or on other tech website coverage.They didn’t improve hyperthreading and then disable it. They removed the feature completely, and netted the die area and power savings from doing so. They probably also took a MT loss, but the die area and power savings could have been redirected to either better usage of the area for more performance, or just direct cost and efficiency savings. Intel’s hyperthreading was always a really inefficient way to gain a small amount of performance anyways. The actual side, published on Techpowerup’s dive, says removing hyperthreading saved them 5% perf/power, 15% perf/area, and 15% perf/power/area. That slide doesn’t appear to be published on Anandtech.
Essentially, they didn’t waste a bunch of transistors on a disabled feature - they did the obvious thing and physically removed the feature from the die. The description here is Anandtech’s fault, not Intel’s. Reply
rgreen1983 - Tuesday, June 4, 2024 - link
Thank you for your reply and the suggestion to check the techpowerup article. I would expect you are correct like the techpowerup article that HT was removed from the design and silicon, but I've also just read the pcworld lunar lake article which seems to suggest otherwise and amazingly has a slide not found in the techpowerup or anandtech articles.What I think might be going on is that lion cove still has HT in the design because Intel wants it for server chips, although I'd argue it's not necessary there either and by the looks of their recent all E core xeons the thread count sensitive clients should be running those anyways. That would explain why they might improve HT. If that is the case is there 2 lion cove designs, one with HT and another without? I just read the wccftech article which suggests this is the case, mentioning "variants" of lion cove.
Since this lion cove core for lunar lake is being made at tsmc, it makes sense they had to make a new design for their fab anyways so maybe they did remove HT, and wccftech says they removed TSX and AMX also. So the lion cove for Intel fab coming to arrow lake/xeon might have HT, will definitely have TSX and AMX, but they might still turn HT off and only enable for xeon.
Regardless yeah the anandtech mention of HT improvements here in relation to lunar lake seems off base. But I still think there is more Intel could clear up on HT status on die and whether there are multiple lion cove designs. Reply
Drumsticks - Tuesday, June 4, 2024 - link
I think they (techpowerup and pcworld) are both right. Per Tomshardware, commenting on Intel removing HT:"As such, Intel architected two versions of the Lion Cove core, one with and one without hyperthreading, so that the threaded Lion Cove core can be used in other applications, like we see in the forthcoming Xeon 6 processors."
I expect the LNL physical design lacks HT, as that's the only way to actually get the performance/area and performance/watt savings. But we'll probably see the version of Lion Cove with hyper threading show up in the Xeon world (although, to be honest, I'm not sure if it's worth it there given the efficiency losses), as well as on Arrow Lake, where higher performance in exchange for an efficiency loss tends to be an acceptable tradeoff for PC Enthusiasts.
The Tomshardware article also points out to me where Anandtech's article summary gets the 30% number: "Intel’s architects concluded that hyperthreading, which boosts IPC by ~30% in heavily threaded workloads, isn’t as relevant in a hybrid design that leverages the more power- and area-efficient E-cores for threaded workloads." - this is coupled with yet another slide that shows Intel quoting hyperthreading as a +30% throughput for +20% Cdyn.
In other words, I think *lunar lake* does not feature hyperthreading - it's physically non-present in the design. Lion Cove the P-Core microarchitecture, on the other hand, has two designs - one with HT physically present (in Arrow Lake and any Xeon SKUs - speculation), and one without (in Lunar Lake only).
On that note, it also implies two different Modules for e-core as well - one with the e-cores not present on the ring bus (in Lunar Lake) and one where it's connected to the ring bus like "normal"
- this being the config in Alder Lake and Raptor Lake (and this is presumably coming in Arrow Lake higher power laptop SKUs and the desktop) Reply
rgreen1983 - Wednesday, June 5, 2024 - link
Thank you for indulging me in this detailed discussion. I think you are right there are 2 lion cove designs. I don't think all the news outlets are aware of it. Reply