Arm Unveils 2024 CPU Core Designs, Cortex X925, A725 and A520: Arm v9.2 Redefined For 3nm
by Gavin Bonshor on May 29, 2024 11:00 AM EST- Posted in
- CPUs
- Arm
- Smartphones
- Mobile
- SoCs
- Cortex
- 3nm
- Armv9.2
- Cortex-A520
- Cortex X925
- Cortex A725

As the semiconductor industry continues to evolve, Arm stands at the forefront of innovation for its core and IP architecture, especially in the mobile space, by pushing the boundaries of technology to deliver cutting-edge solutions for end users. For 2024, Arm's year-on-year strategic advancements focus on enhancing last year's Armv9.2 architecture with a new twist. Arm has rebranded and re-strategized its efforts by introducing Arm Compute Subsystem (CSS), the direct successor to last year's Total Compute Solutions (TSC2023) platform.
Arm is also transitioning its latest IP and Cortex core designs, including the largest Cortex X925, the middle Cortex A725, and the refreshed and smaller Cortex A520 to the more advanced 3 nm process technology. Arm promises that the 3 nm process node will deliver unprecedented performance gains compared to last year's designs, power efficiency and scalability improvements, and new front and back-end refinements to its Cortex series of cores. Arms' new solutions look to power the next-generation mobile and AI applications as Arm, along with its complete AArch64 64-bit instruction execution and approach to solutions geared towards mobile and notebooks, look set to redefine end users' expectations within the Android and Windows on Arm products.
Arm Compute Subsystem (CSS): CSS is the New TCS
The introduction of Arm Compute Subsystem (CSS) marks a significant milestone in Arm's strategy to deliver a holistic and full-rounded computing solution for partners to implement in their new yearly cycle of mobile devices. CSS is a comprehensive platform that integrates hardware, software, and tools to optimize the performance and efficiency of client devices. It is designed to provide a seamless computing experience across various devices, from smartphones and tablets to laptops and even desktop PCs.
When launched last year, the Armv9.2 architecture represented a significant step forward in Arm's roadmap. Still, this year, it's about building on the successes of its predecessors while introducing a host of new features and improvements. One of the key highlights of the revamped Armv9.2 family is the use of enhanced security features, which include memory tagging extensions (MTE) and confidential compute architecture (CCA). These features provide robust protection against various security threats, making devices more secure.
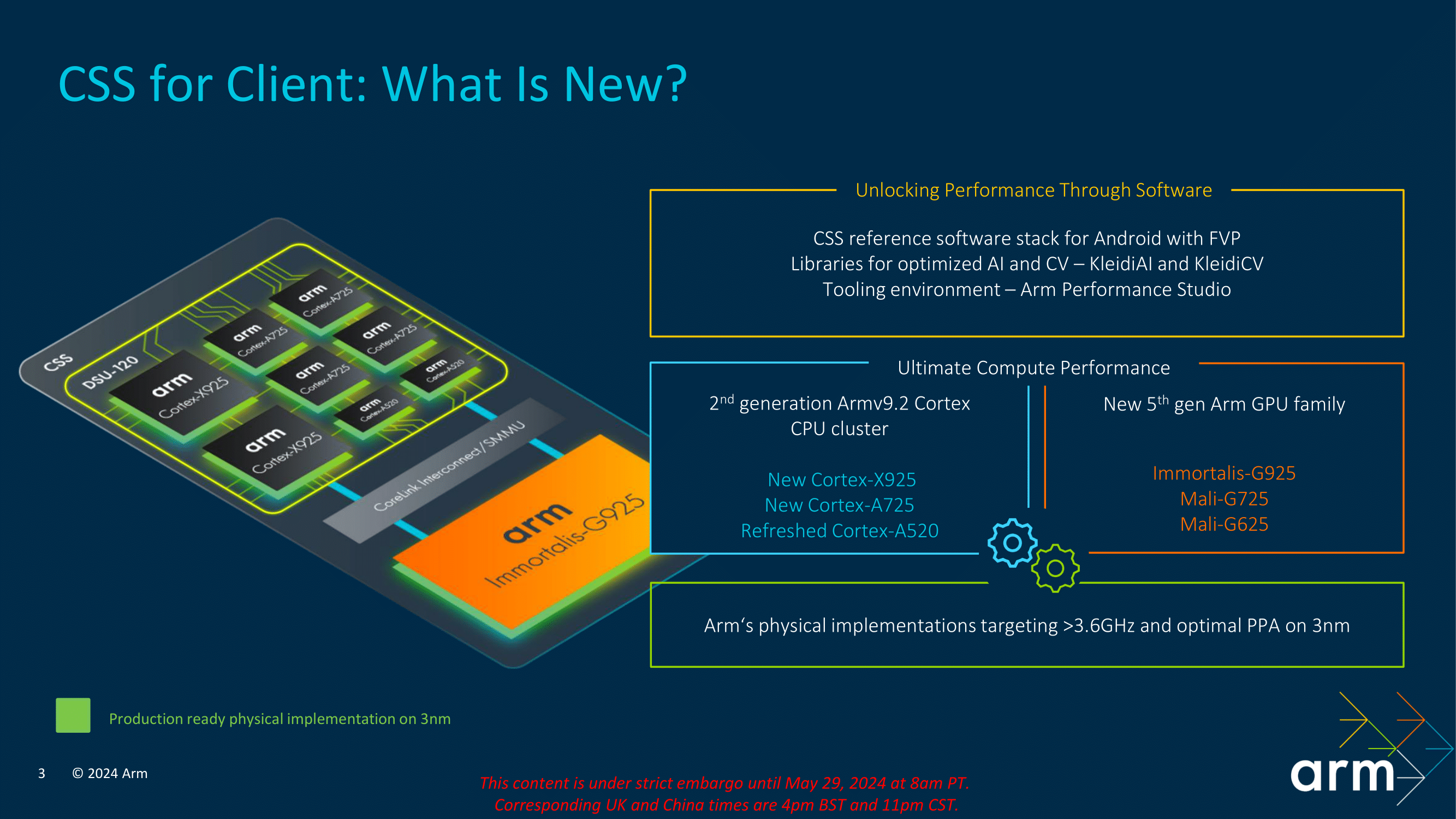
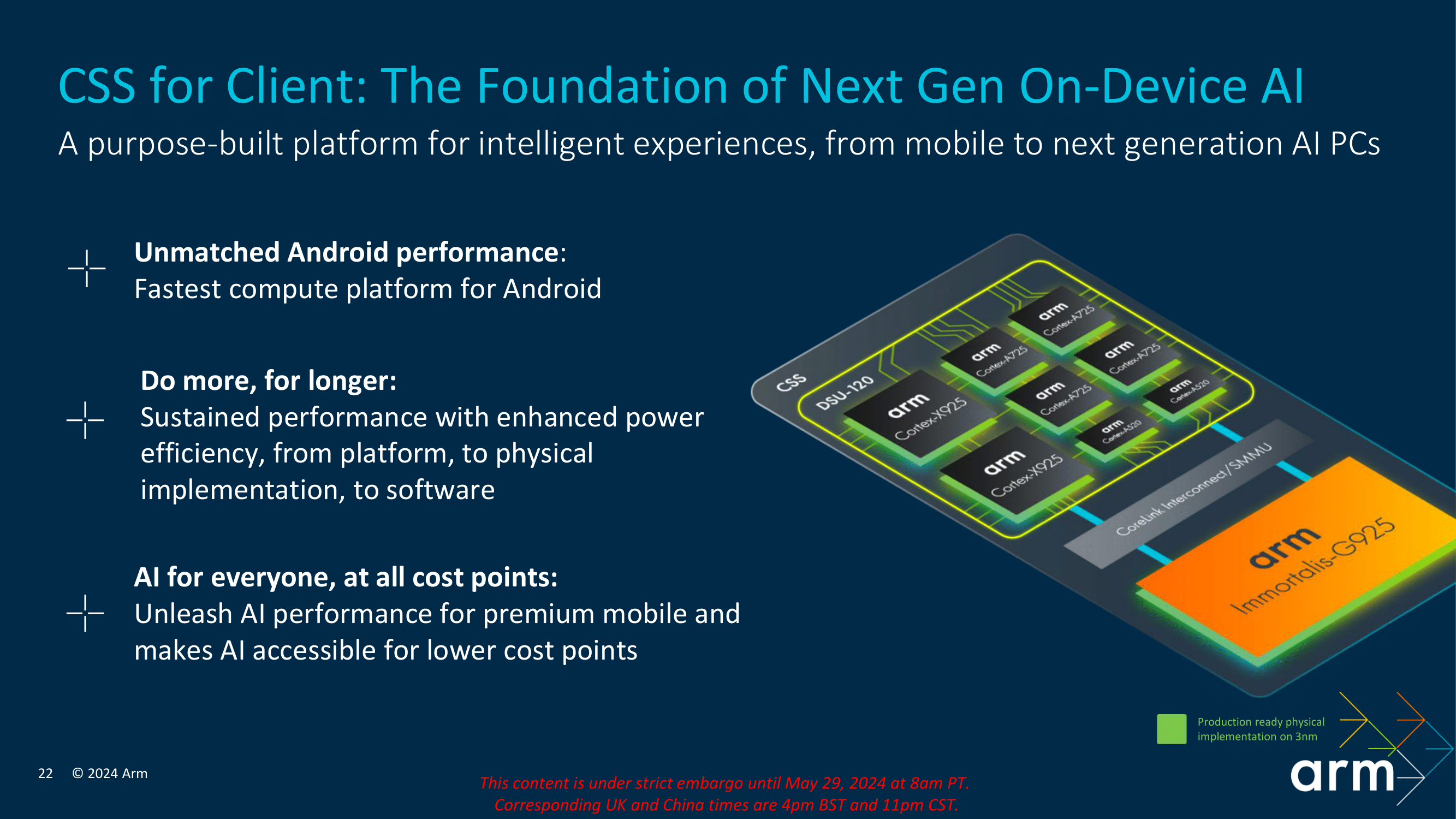
CSS leverages the latest Armv9.2 cores designed for 2024, including the high-performance Cortex X925, the balanced Cortex A725, and the power-efficient and refreshed Cortex A520. These cores are complemented by Arm's new Immortalis G925 GPU, designed to deliver exceptional graphics performance and efficiency in a mobile-sized package. Together, these components form the foundation of what is now called the CSS platform, which aims to provide a powerful and versatile computing solution for modern devices in the mobile sphere.
One of CSS's key features is its robust scalability for different markets, such as mobile and notebooks. The platform is designed to scale across different device form factors and performance requirements, making it suitable for many tasks and applications. Whether it's high-end gaming, professional content creation, or everyday productivity tasks, CSS can be tailored to meet the needs of various use cases.
Arm's Arm Compute Subsystem (CSS) platform represents a significant step forward in IP design and architectural improvements, offering multiple and claiming serious levels of enhancements in performance and efficiency. With the introduction of the second-generation Armv9.2 Cortex CPU cluster, including the new Cortex-X925 (big), Cortex-A725 (middle), and a refreshed Cortex-A520 (little) cores, the CSS platform is designed to deliver the ultimate in mobile computing performance when licensed out to their partners.

Additionally, the CSS platform includes a comprehensive reference software stack for Android, optimized AI backed by new Arm computer vision libraries (KleidiAI and KleidiCV), and robust tooling environments through Arm Performance Studio. This typically holistic approach ensures that Arm's physical implementations achieve speeds greater than 3.6 GHz and offer optimal power, performance, and area (PPA) metrics on the 3 nm node. Speaking of the 3 nm mode, Arm stated that TSMC and Samsung 3 nm are the key options for their CSS core cluster, although it's most likely to be a case of getting fab allocations with TSMC as we are unsure if any will use Samsung over TSMC.
In addition to security enhancements, Armv9.2 on 3 nm also promises substantial performance improvements, especially with the new big core, the Cortex X925, which Arm believes is the new IPC king of the mobile. The architecture has been optimized for higher clock speeds and better levels of efficiency, which in turn should deliver more compute power per watt. This is achieved through several architectural innovations, including wider execution pipelines, improved branch prediction, and enhanced out-of-order execution capabilities. These enhancements boost the cores' Instructions Per Cycle (IPC), ensuring they can easily handle the most demanding workloads.
Transitioning to 3 nm Process Technology
The move to 3 nm process technology represents a significant leap in semiconductor manufacturing, offering substantial improvements in performance, power consumption, and chip density. This transition allows Arm to deliver more powerful and efficient processors capable of handling the most demanding applications efficiently.
One of the primary benefits of the 3 nm process is its ability to pack more transistors into a smaller area, resulting in higher performance and lower power consumption. This is crucial for mobile and portable devices, where battery life and thermal management are critical considerations. The 3 nm process also enables Arm to push out higher clock speeds on the Cortex X925 core, up to 3.8 GHz, to be exact. This enables faster and more responsive computing experiences and pushes overall IPC performance above and beyond what was already achievable.

The combination of the updated Armv9.2 architecture, the new CSS platform, and the jump to the 3 nm process technology, as Arm claims, is designed to roll out significant performance and efficiency enhancements across the board. This should theoretically enable various implementations of their reference CPU Core Cluster designs for devices of all ilks, with two Cortex X cores being the go-to norm now, as opposed to just one from last year's reference design. Benchmarks and real-world tests conducted and presented by Arm, which should be taken with a grain of salt, show substantial gains in single-threaded and multi-threaded performance, making these new solutions ideal for various applications. Arm is even claiming single-threaded IPC leadership with the largest core, the Cortex X925, surpassing what both Intel and AMD are capable of, which is a bold claim.
Regarding power efficiency, the new cores are designed to deliver more compute power per watt, reducing energy consumption and extending battery life. This is particularly important for mobile devices, where users demand long battery life without compromising performance. The improved power efficiency also translates to better thermal management, ensuring that devices remain cool and responsive even under heavy workloads.
In addition to performance and efficiency improvements, the new solutions also bring enhanced security and AI capabilities. The Armv9.2 architecture's memory tagging extensions (MTE) and confidential compute architecture (CCA) provide robust protection against various security threats, ensuring that data and applications remain secure.
The enhanced AI capabilities of the new cores and GPUs are also noteworthy. With AI's increasing importance in modern applications, the new solutions are designed to accelerate AI workloads, delivering faster and more efficient AI processing. This is achieved through dedicated AI accelerators and optimizations that leverage the full potential of the new architecture and process technology.
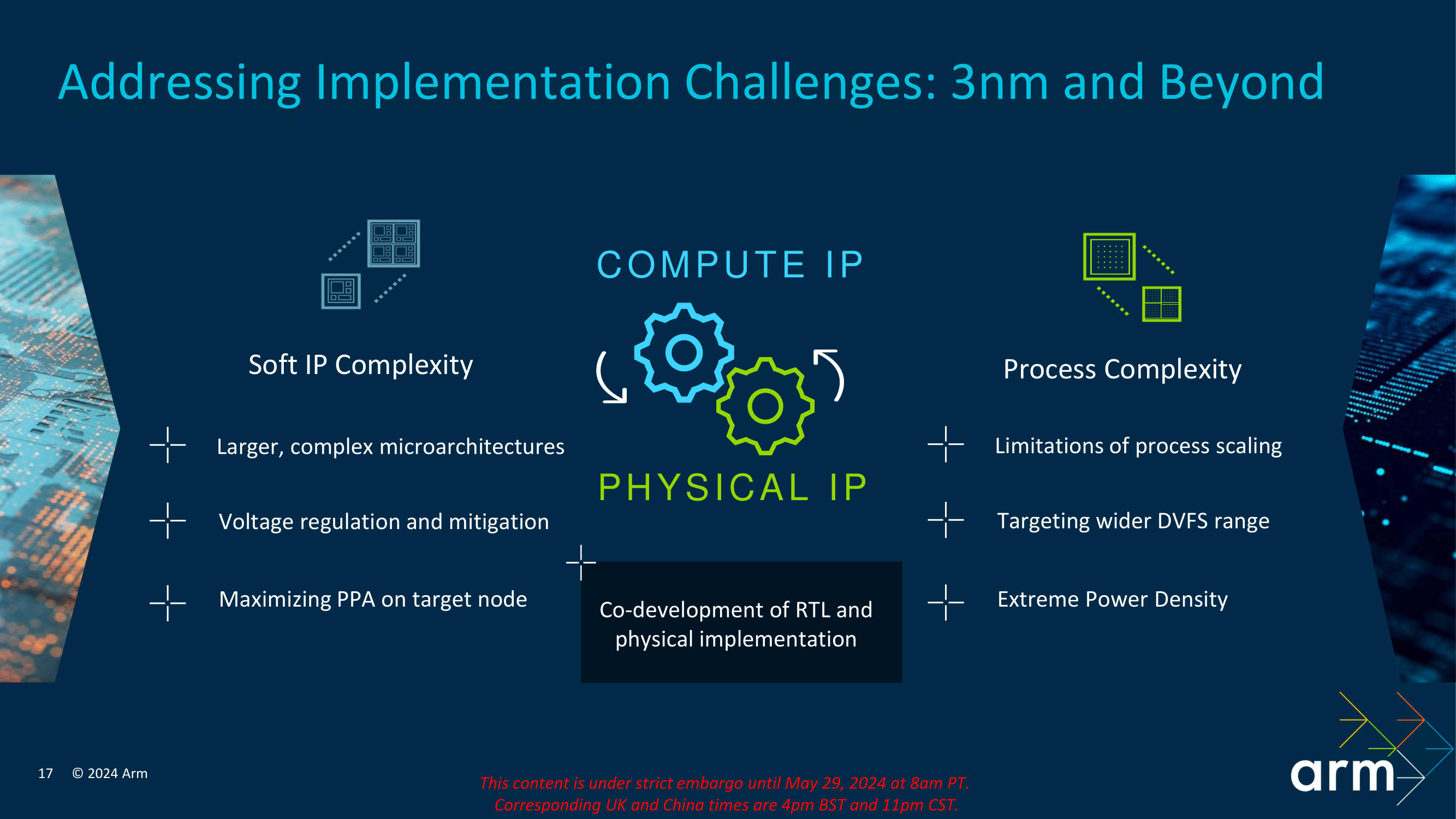
Process technology migration to 3 nm presents many opportunities and challenges for semiconductor manufacturing. For soft IP, bigger and more complex microarchitectures need stronger voltage regulation and mitigation to ensure stability and performance. The key objective is to optimize the right PPA (Power, performance, area) on the target node. For physical IP, process complexity brings its own challenges, including scaling limitations and the requirement to support a wider dynamic voltage and frequency scaling (DVFS) spectrum. Furthermore, with extreme power density, this should mitigate thermal issues, and ensuring things are running efficiently, which is very important in a mobile device
To address these challenges, Arm takes a holistic view of RTL and physical implementation co-development. This ensures that their compute IP can meet performance expectations while overcoming the challenges of advanced process technologies.
Advancements in Armv9.2, CSS, and 3 nm technology open up new possibilities for various applications, including developers accessing the new Arm Kleidi libraries. In the mobile space, these solutions enable more powerful and efficient smartphones and tablets to handle complex tasks such as AI-powered photography, gaming, and productivity.
The new solutions deliver desktop-class performance in portable form factors for the PC market, making them ideal for laptops and 2-in-1 devices. The improved performance and efficiency also benefit professional content creation, allowing for faster rendering, editing, and multitasking.

In the AI and machine learning space, the new solutions provide the compute power needed for advanced AI applications, from natural language processing and computer vision to autonomous systems and robotics. The enhanced AI capabilities ensure these applications run efficiently and effectively, delivering faster and more accurate results.
As Arm continues to push the boundaries of semiconductor technology, the focus on enhancing the Armv9.2 architecture, introducing the CSS platform, and transitioning to the 3 nm process technology marks a significant step forward. These advancements substantially improve performance, power efficiency, and security, enabling a new generation of devices that can easily handle the most demanding applications.
Combining these technologies provides a powerful and versatile computing solution that can scale across different device form factors and use cases. Whether it's high-end gaming, professional content creation, or everyday productivity tasks, Arm's latest solutions are designed to deliver the best possible computing experience.
Good Hardware Benefits From Good Software
Arm's hardware advancements are bolstered by a sophisticated software ecosystem designed to exploit the full potential of its processors. At the heart of this ecosystem are the new Kleidi libraries, which play a crucial role in optimizing artificial intelligence (AI) and computer-based applications. These libraries provide developers with tools tailored to maximize the performance and efficiency of Arm's latest cores.

KleidiAI is a key component that focuses on accelerating AI workloads. It includes a comprehensive set of computational kernels optimized for Arm's architecture, enabling efficient execution of various AI tasks such as machine learning, natural language processing, and data analytics. By offering highly optimized routines for common AI operations, KleidiAI allows developers to achieve significant performance gains while maintaining energy efficiency. This is increasingly important as AI applications become more prevalent in mobile devices, smart home systems, and industrial automation.
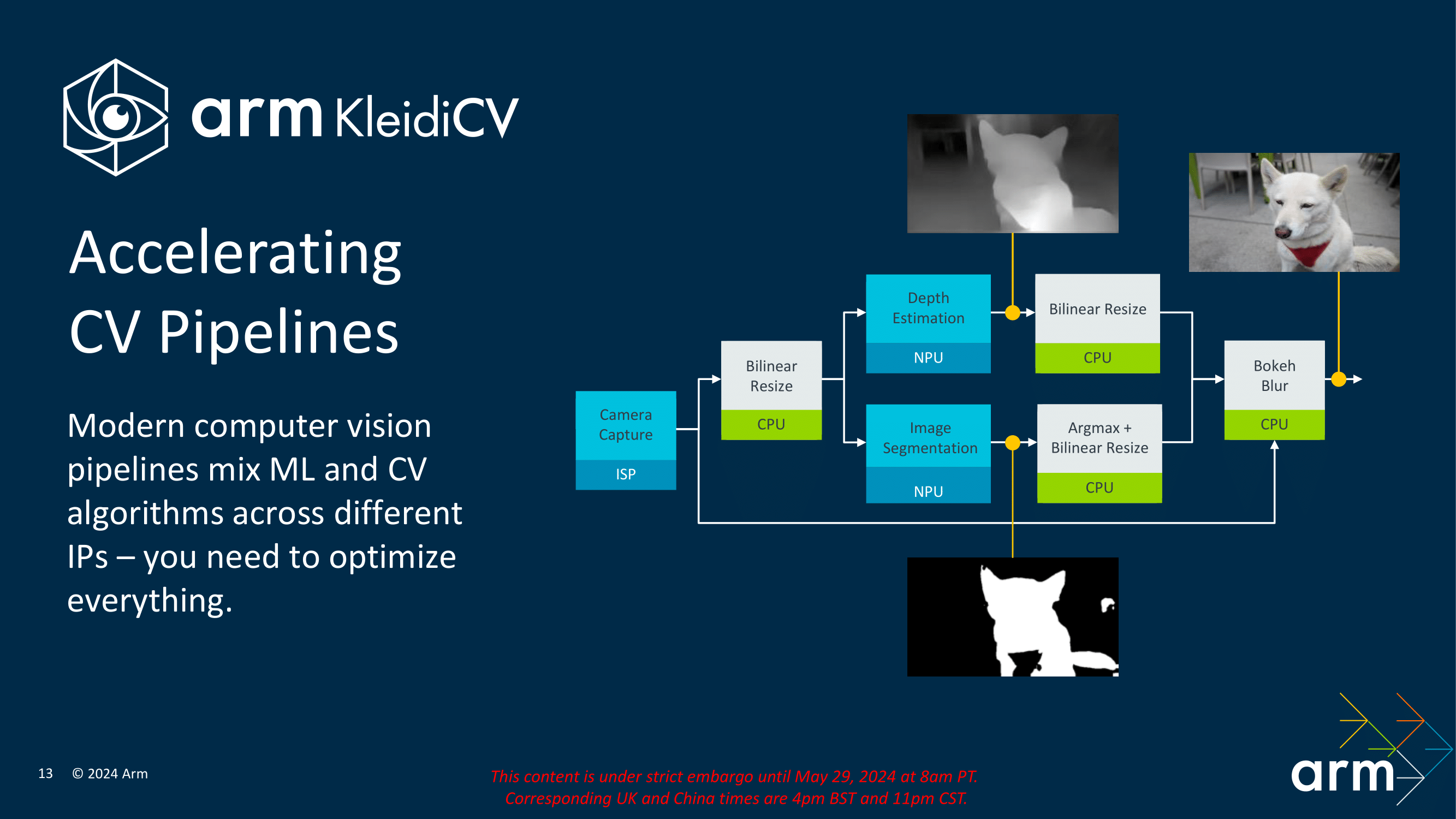
KleidiCV, on the other hand, targets computer vision workloads. This library offers optimized functions for tasks such as image processing, object detection, and scene recognition. Integrating KleidiCV with Arm's architecture ensures that applications can handle visual data quickly and efficiently, making it ideal for use in augmented reality, autonomous vehicles, and intelligent surveillance systems. By leveraging these optimized libraries, developers can build sophisticated applications that run smoothly on Arm-based hardware, fully utilizing the performance and power efficiency improvements provided by the 3 nm process technology.
In addition to the Kleidi libraries, Arm provides a robust set of development tools and platforms. The Arm Compute Subsystem (CSS) platform includes reference software stacks and performance optimization tools like Arm Performance Studio, which offers detailed insights into application performance and helps developers fine-tune their software for maximum efficiency. This comprehensive support system ensures that developers can quickly and effectively bring innovative applications to market, taking full advantage of Arm's latest architectural advancements.
Over the next few pages, we'll break down Arm's improvements within its 2024 CPU cluster, including the new Cortex X925 and Cortex A725 cores and refinements made with the smallest core, the Cortex A520.








55 Comments
View All Comments
SarahKerrigan - Wednesday, May 29, 2024 - link
"The core is built on Arm's latest 3 nm process technology, which enables it to achieve significant power savings compared to previous generations."ARM doesn't have lithography capabilities and this is a synthesizable core. This sentence doesn't mean anything.
meacupla - Wednesday, May 29, 2024 - link
AFAIK, the core design needs to be adapted to the smaller process node, and it's not as simple as shrinking an existing design.Ryan Smith - Wednesday, May 29, 2024 - link
Thanks. Reworded.dotjaz - Wednesday, May 29, 2024 - link
"ARM doesn't have lithography capabilities and this is a synthesizable core"And? Apple also doesn't have litho. You are telling me they can't implement anything with external foundries? Do you even know the basics of modern chip design? DTCO has been THE key to archieve better results for at least half a decade now.
Also this is clearly not just a synthesizable core. ARM explicitly announced this is avaiable as production ready cores, that means the implementations are tied to TSMC N3E and Samsung SF3 via DTCO, and this is the first time ARM has launched with ready for production hard core implementation.
You clearly didn't understand, and that's why it didn't mean anything TO YOU, and probably had to be dumbed down for you.
It actually makes perfect sense to me.
lmcd - Wednesday, May 29, 2024 - link
There was a turnaround time slide that didn't get Anandtech text to go with it that made this more clear, but a skim would miss it.zamroni - Monday, June 17, 2024 - link
it means the logic circuit is designed for 3nm's characteristics, e.g. signal latency, transistor density etc.older cortex designs can be manufactured using 3nm but it won't reach same performance as they were designed to cater higher signal latency of 4nm or older generations
Duncan Macdonald - Wednesday, May 29, 2024 - link
Lots of buzzwords but low on technical content. Much of this reads like a presentation designed to bamboozle senior management.Ryan Smith - Wednesday, May 29, 2024 - link
Similar sentiments were shared at the briefing.continuum - Thursday, May 30, 2024 - link
Whole tone of this article feels like it was written by an AI given how often (compared to what I'm used to in previous articles on this from Anandtech!) certain sentiments like "3nm process" and other buzzwords are used!name99 - Wednesday, May 29, 2024 - link
Not completely true...Interesting points (relative to Apple, I don't know enough about Nuvia internals to comment) include
- 4-wide load (vs Apple 3-wide load) is a nice tweak.
- 6-wide NEON is a big jump. Of course they have to scramble to cover that they STILL don't have SVE or SME; even so there is definitely some code that will like this, and the responses will be interesting. I can see a trajectory for how Apple improves SME and SSVE as a response, probably (we shall see...) also boosting NEON to 256b-SVE2. (But for this first round, still 4xNEON=2xSVE2)
Nuvia, less clear how they will counter.
Regardless I'm happy about both of these and requiring a response from Apple which, in turn, makes M a better chip for math/science/engineering (which is what I care about).
They're still relying on run-ahead for some fraction of their I-Prefetch. This SOUNDS good, but honestly, that's a superficial first response and you need to think deeper. Problem is that as far as prefetch goes, branches are of two forms – near branches (mostly if/else), which don't matter, a simple next line prefetcher covers them; and far branches (mostly call/return). You want to drive your prefetcher based on call/return patterns, not trying to run the if/else fetches enough cycles ahead of Decode. Apple gets this right with an I-prefetcher scheme that's based on call/return patterns (and has recently been boosted to use some TAGE-like ideas).
Ultimately it looks to me like they are boxed in by the fact that they need to look good on phones that are too cheap for a real NPU or a decent GPU. Which means they're blowing most of their extra budget on throughput functionality to handle CPU-based AI.
Probably not the optimal way to spend transistors as opposed to Apple or QC. BUT
with the great side-effect that it makes their core a lot nicer for STEM code! Maybe not what marketing wanted to push, but as I said, I'll take it as steering Apple and QC in the right direction.
I suspect this is part of why the announcement comes across as so light compared to the past few years – there simply isn't much new cool interesting stuff there, just a workmanlike (and probably appropriate) use of extra transistors to buy more throughput.